CrawlSpider爬虫的创建
为什么要有CrawlSpider爬虫
spider是Scrapy框架中的基础爬虫,在翻页的时候,我们是这样操作的:
# 获取下一页
next_href = response.xpath("//a[@id='amore']/@href").get()
if next_href:
next_url = response.urljoin(next_href)
request = scrapy.Request(next_url)
yield request
而比spider高级一点的CrawlSpider爬虫,其主要特色是不用手动yield,可以实现遇到指定URL后自动翻页,这就比spider方便一些。
创建CrawlSpider爬虫的命令:
scrapy genspider -t crawl [爬虫名字] [域名]
参考上面的创建流程,我们在终端中输入下面四行代码:
cd /Users/pangyuxuan/lyCrawlSpider # cd到文件夹lyCrawlSpider
scrapy startproject lycs # 创建Scrapy项目,项目名称为lycs
cd lycs # 进入项目路径
scrapy genspider -t crawl lycSpider
# 创建crawl爬虫,爬虫名称为lycSpider,目标域名为https://www.lieyunwang.com/
得到了这样的爬虫文件:
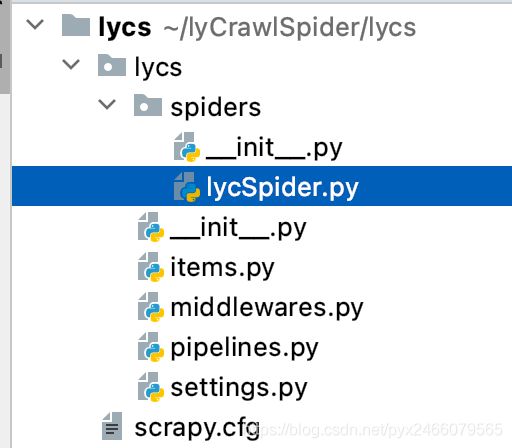
与spider的区别——“规则”的定义
spiders文件夹中的lycSpider.py与基础案例中的gsw_spider.py相对应,其默认的代码如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class LycspiderSpider(CrawlSpider):
name = 'lycSpider' # 没变
allowed_domains = ['https://www.lieyunwang.com/'] # 没变
start_urls = ['http://https://www.lieyunwang.com//'] # 没变
rules = ( # 满足rules时自动爬取,不用再手动yield
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
其中:
LinkExtractor
使用LinkExtractor可以在页面中自动找到所有满足规则的url,实现自动的爬取。
class scrapy.linkextractors.LinkExtractor(allow = (),deny = (),allow_domains = (),deny_domains = (),deny_extensions = None,restrict_xpaths = (),tags = ('a','area'),attrs = ('href'),canonicalize = True,unique = True,process_value = None)
常用参数:
allow :允许的url——所有满足这个正则表达式的url都会被提取。
deny :禁止的url——所有满足这个正则表达式的url都不会被提取。
allow_domains :允许的域名——只有在这个里面指定的域名的url才会被提取。
deny_domains :禁止的域名——所有在这个里面指定的域名的url都不会被提取。
restrict_xpaths :使用xpath——和allow共同过滤链接。
Rule
用来定义这个url爬取后的处理方式,比如是否需要跟进,是否需要执行回调函数等。
class scrapy.spiders.Rule(link_extractor, callback = None, cb_kwargs = None, follow = None,process_links = None, process_request = None)
常用参数:
link_extractor :一个LinkExtractor对象,用于定义爬取规则
callback :满足这个规则的url,应该要执行哪个回调函数。
follow :指定根据该规则从response中提取的链接是否需要跟进,也就是需不需要找这个链接的页面里还有没有其他符合要求的链接
process_links :从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接
实操
先在settings.py里关闭协议、设置ua
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : '我的user-'
}
调整start_urls
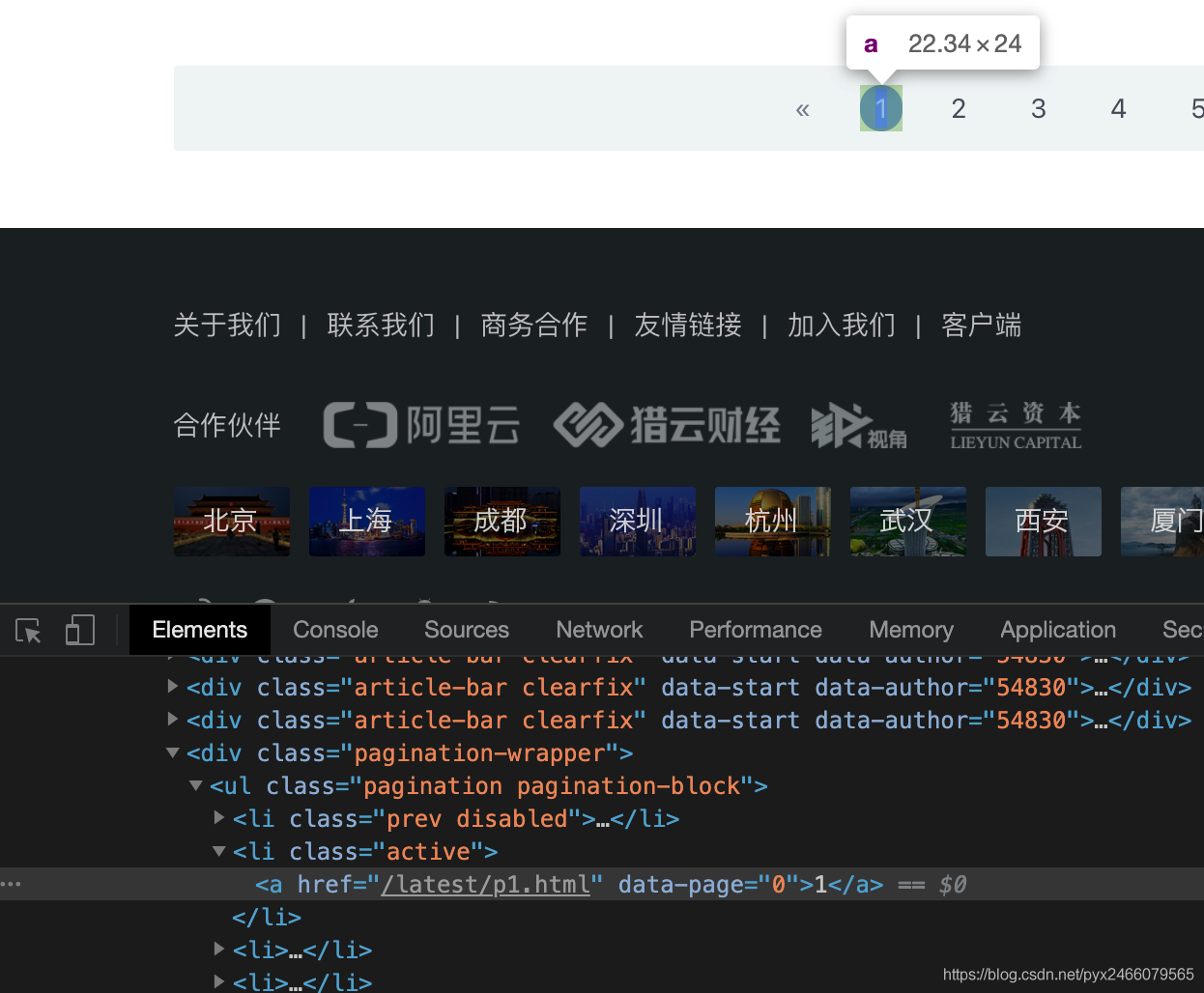
在页码1处点击检查,点击下方的链接进入第一页,复制此时浏览器内的链接即可:
start_urls = ['https://www.lieyunwang.com/latest/p1.html']
编写rules
我们的思路是:
找到每一页的链接,再从每一页里找每一篇文章的链接。
规则应该是这样:
rules = (
Rule(LinkExtractor(allow=r'/latest/p\d+\.html'), follow=True),
Rule(LinkExtractor(allow=r'/archives/\d+'), callback="parse_detail", follow=False),
)
其中:
第一条规则用于找到每一页,因为页面的格式都是这样:
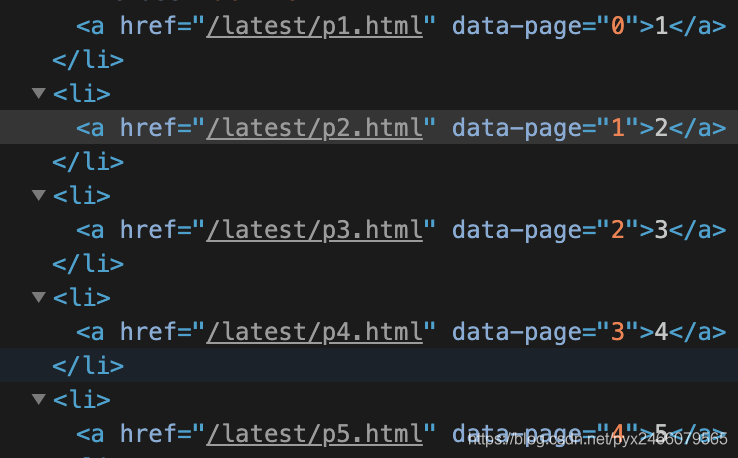
所以使用正则表达式匹配字符,即为/latest/p\d+\.html,其中:
页码可能是两位数,所以用d+
.是特殊符号,需要额外加一个反斜杠\
此外,找到每一页并不是终点,我们还需要找这一页里的文章,也就是还需要从这一页里面找其他链接,所以follow=True
第二条规则用于找每一页里的所有文章,因为文章的格式都是这样:
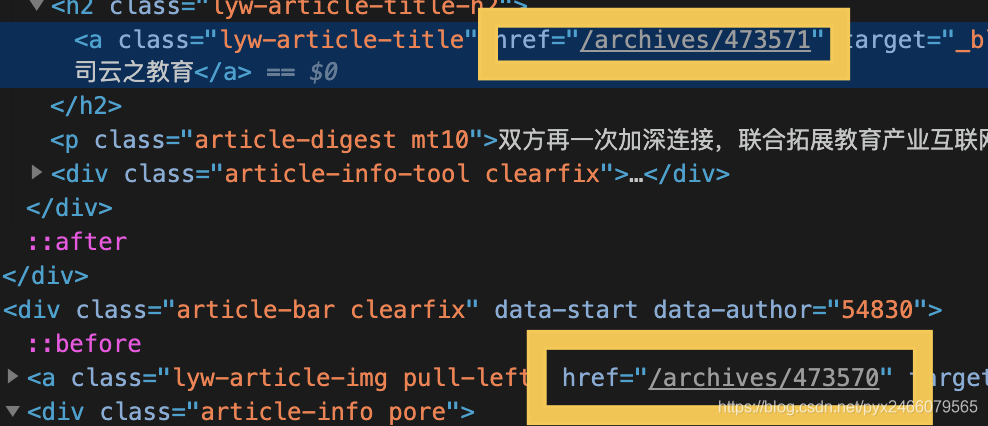
所以我们的正则表达式写为/archives/\d+
此外,我们找到文章以后,并不需要通过该文章找其他文章,所以follow=False,另外我们需要调用函数来获取它的内容了,所以callback="parse_detail",其中parse_detail是后面要写的函数
在parse_detail函数里测试一下我们的rules写没写对:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class LycspiderSpider(CrawlSpider):
name = 'lycSpider'
allowed_domains = ['lieyunwang.com']
start_urls = ['https://www.lieyunwang.com/latest/p1.html']
rules = (
Rule(LinkExtractor(allow=r'/latest/p\d+\.html'), follow=True),
Rule(LinkExtractor(allow=r'/archives/\d+'), callback="parse_detail", follow=False),
)
def parse_detail(self, response):
print("="*50)
print(response.url) # 输出找到的url来验证
print("="*50)
ps. 运行方法与前面的运行方法一致,都是新建一个start.py文件,可以先跳到后面去看一下start.py文件怎么写,也可以省略这一步测试~~
数据解析与存储
方便起见,我们只爬取文章的标题title、导语conclude和段落内容content
数据解析和存储的方式与之前的完全一样,在这里直接给出操作流程,不做过多的赘述:
1. 使用xpath获取三个部分的内容
直接右键-检查-copy xpath即可
def parse_detail(self, response):
title = response.xpath('//*[@id="fixed_container"]/div[1]/div[2]/div[1]/h1/text()').getall()
title = "".join(title).strip()
content = response.xpath('//*[@id="main-text-id"]').getall()
content = "".join(content).strip()
conclude = response.xpath('//*[@id="fixed_container"]/div[1]/div[2]/div[3]').getall()
conclude = "".join(conclude).strip()
2. 在settings.py中解除piplines的注释
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lycs.pipelines.LycsPipeline': 300,
}
3. 编写piplines.py
from itemadapter import ItemAdapter
import json
class LycsPipeline:
def open_spider(self,spider):
self.fp = open("简讯.txt",'w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(json.dumps(dict(item),ensure_ascii=False)+'\n')
return item
def close_spider(self,spider):
self.fp.close()
4. 编写items.py
import scrapy
class LycsItem(scrapy.Item):
title = scrapy.Field() # 标题
content = scrapy.Field() # 导语
conclude = scrapy.Field() # 结论
5. 在lycSPider.py里导入items并传入要保存的参数
... # 省略其他部分代码
from ..items import LycsItem
... # 省略其他部分代码
def parse_detail(self, response):
... # 省略其他部分代码
item = LycsItem(title=title,content=content,conclude=conclude)
return item # 写yield应该也可以
运行
CrawlSpider的运行与spider完全一样,都是在终端输入命令以运行,方便起见,我们还是编写start.py文件来实现在pycharm里的运行:
from scrapy import cmdline
cmdline.execute("scrapy crawl lycSpider".split(" "))
ps. 为了秀一把这里给出了另一种发送命令的方式,本质上与之前那一种是一样的。
直接成功
总结
相比于spider,CrawlSpider的核心优势就是可以自己找新的页面,不用我们手动设置翻页方法。
最终的参考代码
lycSpider.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import LycsItem
class LycspiderSpider(CrawlSpider):
name = 'lycSpider'
allowed_domains = ['lieyunwang.com']
start_urls = ['https://www.lieyunwang.com/latest/p1.html']
rules = (
Rule(LinkExtractor(allow=r'/latest/p\d+\.html'), follow=True),
Rule(LinkExtractor(allow=r'/archives/\d+'), callback="parse_detail", follow=False),
)
def parse_detail(self, response):
title = response.xpath('//*[@id="fixed_container"]/div[1]/div[2]/div[1]/h1/text()').getall()
title = "".join(title).strip()
content = response.xpath('//*[@id="main-text-id"]').getall()
content = "".join(content).strip()
conclude = response.xpath('//*[@id="fixed_container"]/div[1]/div[2]/div[3]').getall()
conclude = "".join(conclude).strip()
item = LycsItem(title=title,content=content,conclude=conclude)
return item
items.py
import scrapy
class LycsItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
conclude = scrapy.Field()
piplines.py
from itemadapter import ItemAdapter
import json
class LycsPipeline:
def open_spider(self,spider):
self.fp = open("简讯.txt",'w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(json.dumps(dict(item),ensure_ascii=False)+'\n')
return item
def close_spider(self,spider):
self.fp.close()
settings.py
BOT_NAME = 'lycs'
SPIDER_MODULES = ['lycs.spiders']
NEWSPIDER_MODULE = 'lycs.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : '我的user-agent'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lycs.pipelines.LycsPipeline': 300,
}
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责,本站只提供参考并不构成任何投资及应用建议。本站是一个个人学习交流的平台,网站上部分文章为转载,并不用于任何商业目的,我们已经尽可能的对作者和来源进行了通告,但是能力有限或疏忽,造成漏登,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。


