python实现代码
eps:邻域半径(float)
MinPts:密度阈值(int)
.fit(X):对待聚类的数据集进行聚类
用法:指定邻域半径和密度阈值,这两个参数对应于不同的数据集需要进行调整,然后直接调用fit(X) 进行数据集的聚类。
# -*- coding: utf-8 -*-
# @Time : 2020/12/21 16:34
# @Author : CyrusMay WJ
# @FileName: cyrus_dbscan.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/Cyrus_May
import sys
import logging
import numpy as np
import random
class CyrusDBSCAN(object):
def __init__(self,eps=0.1,MinPts=3):
"""
:param eps: 邻域半径
:param MinPts: 密度阈值
"""
self.__build_logger()
self.eps = eps
self.MinPts = MinPts
def __build_logger(self):
self.logger = logging.getLogger()
self.logger.setLevel(logging.INFO)
screen_handler = logging.StreamHandler(sys.stdout)
screen_handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(module)s.%(funcName)s:%(lineno)d - %(levelname)s - %(message)s')
screen_handler.setFormatter(formatter)
self.logger.addHandler(screen_handler)
def fit(self,X):
# 初始化数据点状态及索引号
self.X = np.array(X)
global index,state,class_cluster
index = [i for i in np.arange(X.shape[0])]
state = [0] * X.shape[0]
class_cluster = 1
while 1:
if self.choice() is not None:
# 从未划分的数据点中随机选择一个
point = self.choice()
# 计算在其领域半径内的点
not_use_index = self.not_use_point()
temp = []
for i in not_use_index:
if i != point:
if self.cal_dist(self.X[i, :], self.X[point, :]) <= self.eps:
temp.append(i)
if len(temp) >= self.MinPts:
self.logger.info("搜索到第{}簇!".format(class_cluster))
self.cal_eps_count([point])
self.logger.info("第{}簇搜索完成!".format(class_cluster))
class_cluster += 1
else:
state[point] = "noise"
else:
break
return state
def cal_eps_count(self,points):
flag = []
for point in points:
temp = []
for i in self.not_use_point():
if self.cal_dist(self.X[i,:],self.X[point,:]) <= self.eps and i != point:
state[i] = class_cluster
temp.append(i)
self.logger.info("第{}簇新增一个数据点!".format(class_cluster))
if len(temp) >= self.MinPts:
flag += temp
if flag:
return self.cal_eps_count(flag)
def cal_dist(self,x1,x2):
return (((x1-x2)**2).sum())**0.5
def not_use_point(self):
temp = []
for i in index:
if state[i] in [0,"noise"]:
temp.append(i)
return temp
def choice(self):
temp = []
for i in index:
if state[i] == 0:
temp.append(i)
if len(temp) == 1:
state[temp[0]] = "noise"
return None
elif len(temp) == 0:
return None
else:
return random.choice(temp)
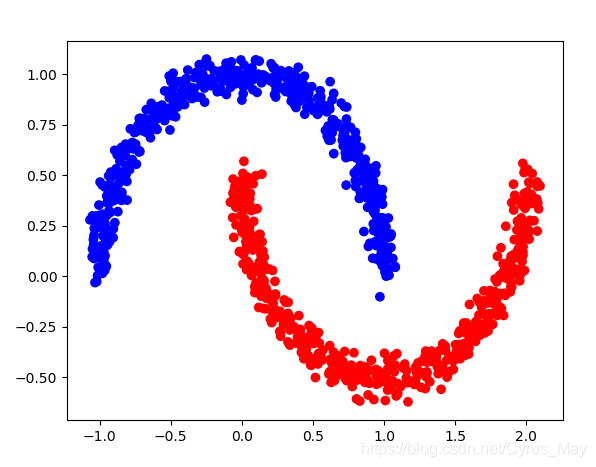
计算实例
对加入噪声的月亮形状数据集进行聚类
if __name__ == '__main__':
dbscan = CyrusDBSCAN(eps=0.25,MinPts=3)
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
moons = make_moons(n_samples=1000,noise=0.05)
y = dbscan.fit(moons[0])
dbscan.logger.info(y)
plt.scatter(moons[0][:, 0], moons[0][:, 1], c=[["r", "b"][i-1] if i != "noise" else "g" for i in y])
plt.show()
2020-12-21 21:14:32,952 - cyrus_dbscan.cal_eps_count:68 - INFO - 第2簇新增一个数据点!
2020-12-21 21:14:32,952 - cyrus_dbscan.cal_eps_count:68 - INFO - 第2簇新增一个数据点!
2020-12-21 21:14:32,955 - cyrus_dbscan.fit:53 - INFO - 第2簇搜索完成!
2020-12-21 21:14:32,956 - cyrus_dbscan.<module>:103 - INFO - [1, 1, 1, 2, 1, 2, 2, 2, 1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 1, 2, 2, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 1, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 2, 1, 2, 1, 1, 1, 2, 1, 2, 1, 1, 1, 2, 2, 1, 1, 2, 1, 2, 2, 1, 1, 2, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 1, 2, 1, 2, 1, 1, 1, 2, 2, 2, 1, 2, 1, 1, 2, 1, 2, 1, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 2, 2, 1, 1, 2, 2, 2, 1, 1, 1, 1, 2, 1, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 1, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 1, 2, 2, 2, 1, 2, 1, 1, 1, 1, 1, 2, 2, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 2, 1, 2, 2, 2, 1, 2, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 2, 1, 2, 2, 2, 1, 1, 1, 2, 1, 2, 2, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, 2, 1, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 1, 2, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 2, 1, 2, 1, 1, 1, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 1, 2, 1, 2, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, 1, 2, 1, 2, 2, 2, 1, 2, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 2, 1, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1, 2, 1, 1, 2, 2, 1, 2, 1, 2, 1, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 1, 2, 2, 1, 1, 1, 2, 2, 2, 2, 1, 2, 1, 2, 1, 1, 2, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2, 1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 2, 1, 2, 2, 1, 2, 1, 2, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1, 2, 1, 1, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 2, 1, 2, 1, 1, 1, 2, 1, 1, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 1, 1, 2, 1, 1, 2, 1, 1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 2, 1, 2, 1, 1, 2, 1, 1, 2, 1, 2, 2, 2, 1, 2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 1, 1, 1, 2, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 2, 1, 2, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 2, 1, 1, 2, 1, 1, 2, 1, 2, 2, 1, 1, 1, 2, 1, 1, 1, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 2, 1, 1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 1, 2, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1, 1, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 1, 2, 2, 2, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 1, 1, 1, 1, 2, 1, 2]
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责,本站只提供参考并不构成任何投资及应用建议。本站是一个个人学习交流的平台,网站上部分文章为转载,并不用于任何商业目的,我们已经尽可能的对作者和来源进行了通告,但是能力有限或疏忽,造成漏登,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。


