
Yann LeCun大神曾经说过,“对抗训练是近些年来机器学习领域中炫酷的想法”。没错,对抗训练已经在深度学习的圈子里掀起了不小的涟漪。本文将介绍三篇基于Ian Goodfellow开创性工作论文。
笔者曾在一篇博文中简单提过Ian Goodfellow的生成对抗网络论文,《九篇深度学习好文》。这些网络模型的基本思想就是基于两个模型:一个生成模型和一个判别模型。
判别模型的任务是判断一张给定的图片是真实的还是经过人工修饰。生成器的任务是模拟生成与图集中的图片相似的合成图片。我们可以把这个过程看作一种零和游戏。
论文中打了个比方,生成模型类似“一个假币制造团伙,试图生产和使用假币”,而判别模型类似“金融警察,发现和查处假币”。生成器不断地愚弄判别器,而判别器试图反抗生成器的愚弄。由于模型训练通过交替优化,两种模型终都能达到“无法区分真品和赝品”的程度。
对抗网络的一大用途就是在经过充分训练之后,能够生成以假乱真的图片。下面是Goodfellow 在2014年发表的论文中给出的例子。

如图所示,生成器模拟生成的手写数字和人脸图片非常相似,而模拟CIFAR-10数据集生成的图片则略逊色。
为了改善这一现象,Emily Denton, Soumith Chintala, Arthur Szlam 和 Rob Fergus等人发表了一篇论文《Deep Generative Image Models using Laplacian Pyramid of Adversarial Networks》。这篇文章的主要贡献在于提供了一种网络模型结构,利用这种网络生成的高质量图片对人类评判者的蒙蔽概率接近40%。
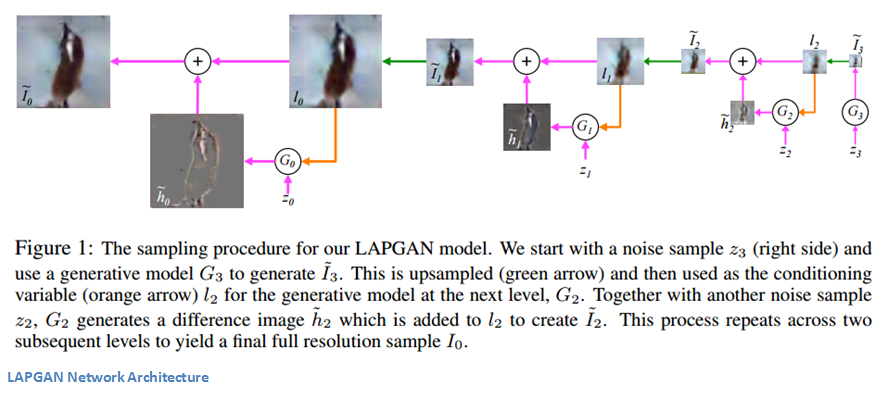
在讨论文章细节之前,我们先来回顾生成器在GAN模型中发挥的作用。它需要生成大量复杂的图片来迷惑经过训练的判别器 —— 乍一看这项任务并不轻松。该文作者们所采取的方法是用多个CNN模型以此生成不同尺度的图片。作者Emily Denton在LAPGANs的讲座中说到:
“低分辨率的图片很容易生成。依照低分辨率的图片生成另一张分辨率稍高的图片也不是那么困难。”
此文采用的方法是构造一组生成模型的拉普拉斯金字塔。有些读者可能还不熟悉,可以参考阅读这篇文章。基本的思想是金字塔每一层表示了某个尺度下图片包含的信息。相当于对原始图片按尺度做了层级分解。
一个简单的GAN模型需要输入和输出两部分。生成器按照概率分布输入一个噪声向量,输出一张图片。判别器输入这张图片(或是训练集中的一张真实图片),输出一个分数,表示该图片的真实性。接着,我们来看看条件GAN(CGAN)。它的主体部分与GAN都相同,区别在于生成器和判别器还需要输入额外的信息。这种信息类似于某种类别标签或是另一张图片。
作者们提出了一组卷积网络模型,金字塔的每一层都对应一个卷积网络。传统的GAN结构只用一个生成器来产生整张图片,他们采用的方法是用一组CNN产生一系列分辨率逐渐提高的图片。
每一层都对应独立的CNN,并且都基于两部分训练,一张低分辨率的图片以及一个噪声向量(传统GAN的输入只有后者)。这也是CGAN思想的实践之处。它的输出是一张合成图片,升采样之后作为金字塔后一级的输入。因为在每个层级的生成器能够利用来自不同分辨率的信息,以便在各个层级中创建更细粒度的输出,所以此方法是有效的。

这篇论文发表于去年六月,主要介绍将文字描述转换为图片的方法。例如,网络模型的输入可以是“一朵粉红色花瓣的花”,输出就是包含这些特征的一幅图片。这项任务由两部分组成。一方面通过自然语言处理技术来分析和理解输入的文本信息,另一方面是生成准确和自然的图片的生成模型。
论文作者认为,从文字到图像的过程比图像到文字的过程难很多倍(参加Karpathy的论文)。不仅因为像素点的数量非常多,而且不能把整个任务拆解为每一步预测下一个词语(图像到文字的方式工作)。
论文中所采用的方法是基于由递归文本编码器生成的文本特征来训练一个GAN模型(详细内容参考这篇论文)。生成器和判别器在各自的网络结构中使用这些特征。这也是GAN连接输入的文本描述和输出的合成图像的桥梁。
我们首先来看生成器。噪声向量z以及文本编码是网络的输入。文本编码是一种封装输入描述信息的方式,随后它被拼接到噪声向量(参见下图)。然后用逆卷积层将输入向量转化为合成图片。
判别器输入一张图片,经过一组卷积层(包括 BatchNorm 和 ReLU)。终输出一个表示图片真实度的分数。
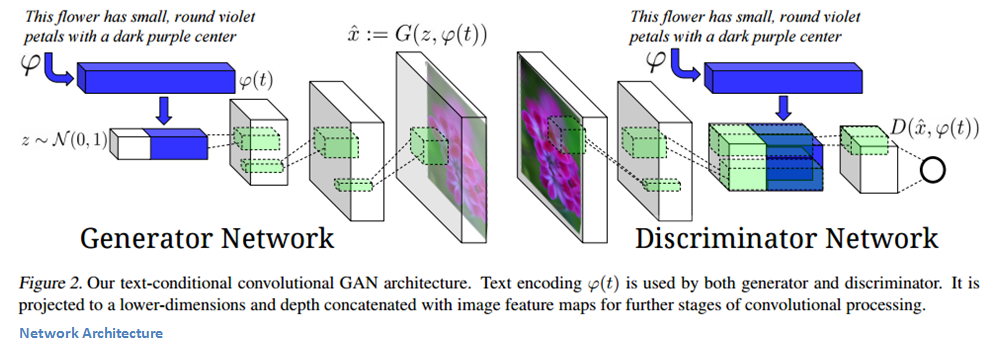
这个模型有趣的一点是它的训练方式。如果你仔细考虑需要解决的任务,会发现生成器有两项工作需要完成。一项是生成真实和伪造的图片,另一项是要确保生成的图片与文字描述相关。同样,判别器也需要考虑这两方面的因素,确保伪造图片或者与描述不匹配的图片被检测到。
为了创建这些通用的模型,作者用三种类型的数据进行训练:{真实图像,正确文本},{假图像,正确文本},和{真实图像,错误文本}。对于后一组训练数据,判别器必须找出与文字描述不匹配的图像(即使他们看起来很自然)。

作为在此领域进行快速创新的证明,Twitter的团队在不久前发布了这篇论文。此篇论文中介绍的模型是超分辨率生成对抗网络(SRGAN)。此文的主要贡献是发明了一种全新的损失函数(比普通的MSE更好),使得网络模型能够根据严重降采样的图像恢复出逼真的纹理和细节。
我们先来看看这个新的损失函数。这种损失函数可以分为两部分:对抗损失和内容损失。从上层角度分析,对抗损失鼓励看起来自然的图像(它们像是来自数据集),内容损失确保新的高分辨率图像具有原始低分辨率图像的类似特性。
接着我们深入到细节。对同一张图片,我们分别准备一个高分辨率版本和一个低分辨率版本。接着训练生成器,使根据低分辨率图片输出的合成图片,尽可能接近高分辨率版本。此输出被称为超分辨图像。然后,训练判别器来区分这些图像。
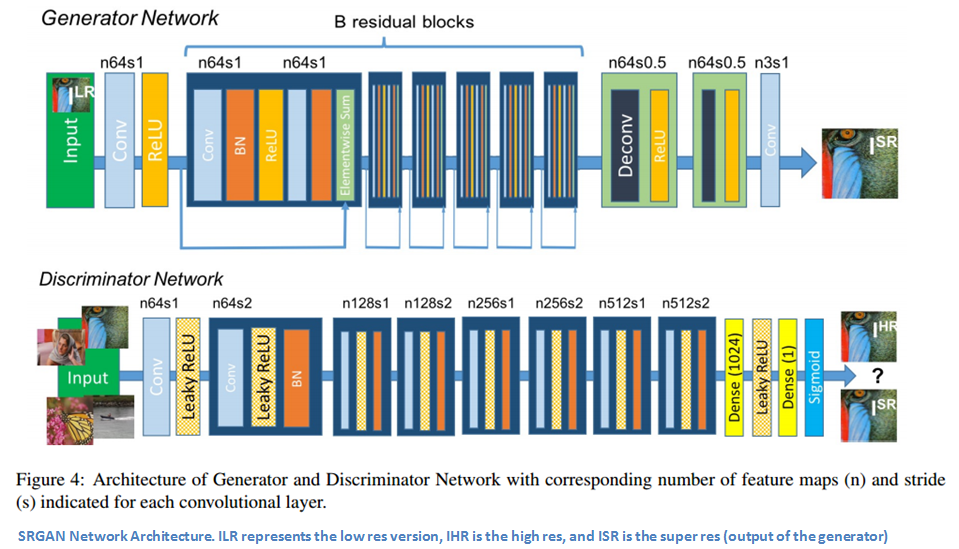
我们再回到新的损失函数。它实际上是多个独立损失函数的加权和。部分是内容损失,这实际上是新的重建图像(网络输出)与实际的高分辨率图像之间的欧氏距离。按照作者的理解,这样做的主要目标是确保两图像的内容相似,将它们送入训练好的ConvNet模型后看各自的特征激活情况。
作者定义的另一种主要损失函数是对抗损失。这类似于传统的GAN。它鼓励输出与原始数据分布类似的结果。有了这个新的损失函数,生成器确保输出更高分辨率的自然图像,却仍然保留与低分辨率图像类似的像素空间。

GAN采用了大规模的无监督式训练(我们只需要一个真实的图集,不需要标注等等信息)。这意味着我们可以利用现在大量的非结构化图像数据。训练结束后,我们可以使用输出或中间层作为特征提取器,用于给其它分类器提供特征,它不需要太多的训练数据就能达到不错的精度。
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责,本站只提供参考并不构成任何投资及应用建议。本站是一个个人学习交流的平台,网站上部分文章为转载,并不用于任何商业目的,我们已经尽可能的对作者和来源进行了通告,但是能力有限或疏忽,造成漏登,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。

