
本文主要介绍频繁模式挖掘算法,以及其典型的应用和Apriori算法。
频繁模式挖掘,相关性挖掘,关联规则学习,Apriori算法等等,这些看似不同但本质上一样的概念一直以来被用于描述数据挖掘的相关内容。所谓的数据挖掘是指利用统计的方法从某个数据集中发现有价值的、未被人所知的规律。我们用分类或者聚类的方法,只是想挖掘数据集内各个子集的相互关系,寻找哪些事物经常同时出现,哪些事物相互依附,以及哪些事物存在联系。
因此,我们这个视角来理解数据挖掘这个概念。在后文中,我将用频繁模式挖掘来指代数据挖掘这一概念,也有人喜欢称为关联挖掘。
频繁模式指的是在数据集中频繁出现的一类模式。频繁项集指的是由包含某一类频繁模式的元素组成的集合。因此,频繁模式挖掘也常被叫做频繁项集挖掘。
购物篮分析(或是亲密性分析)是介绍频繁模式挖掘的佳案例,它是众所周知的频繁模式挖掘应用之一。购物篮分析试图从消费者加入购物篮的商品中挖掘出某种模式或者关联,可以是真实的购物篮,也可以是虚拟的,并且给出支持度或是置信度。这一方法在用户行为分析中存在巨大的价值。
将购物篮分析推而广之就成了频繁模式挖掘,实际上它与分类非常类似,只是通过相互的关联来预测属性或是属性的组合(不仅仅是预测类别)。因为关联不需要预标记类别标签,所以它属于非监督式学习。
如果我们把所有的物品都看作是我们集合中的一个元素(或是商店售卖的所有商品,或是用于欺诈检测分析的所有交易记录),那么每个元素可以用一个布尔值表示,表示该元素是否出现在某个特定的“篮子”里。每个篮子就是一个布尔值的向量,而向量的长度由集合的大小决定。所有可能的向量组成的矩阵就是一个数据集。
我们接下来就用这个布尔向量集合来分析元素之间的关联关系、相关关系和挖掘模式。表示这些模式的常用的方法之一是通过关联规则,其中的一个例子如下:
milk => bread [support = 25%, confidence = 60%]
我们怎么知道一条规则的价值究有多少呢?这时候就需要用到支持度和置信度这两个指标了。
支持度是度量模式或者物品成对出现的绝对次数。在上面的例子里,25%的支持度表示牛奶和面包被共同购买的次数占到所有交易次数的25%。
置信度是度量模式或者物品成对出现的相对次数。在上面的例子里,60%的置信度表示购买牛奶的客户中,有60%的客户同时也购买了面包。
在一个给定的场景中,通常需要置信度和支持度都大于设定的阈值,这条关联规则才能成立,这条规则才有利用价值。
Apriori是广为人知的频繁模式挖掘算法。还是以购物篮分析为例,Apriori的数据集是一个巨大的稀疏矩阵,每一行是一单交易,每一列表示这单交易成交的若干个商品。
假设总共有n个商品,Apriori算法首先生成一个候选商品列表长度是2~n-1。用组合的方式可以计算出所有可能的组合情况的个数:
C(n,n-(n+2)) + C(n,n-(n+3)) + … + C(n,n-1)
上式也可以用二项分布的系数来表示。
如果数据集非常庞大,那这个计算过程会很耗时。

算法需要输入小支持度的阈值。首先,这个算法生成一个候选集合的列表,包括了了数据集中可能出现的所有组合。候选集合生成后,如果其在交易记录中出现的频率大于阈值,则认为它是一个频繁项集。

遍历频繁项集的集合可以很容易得到关联规则及其置信度。置信度的计算公式如下:
Confidence(A=>B) = Support(AUB) / Support(A)
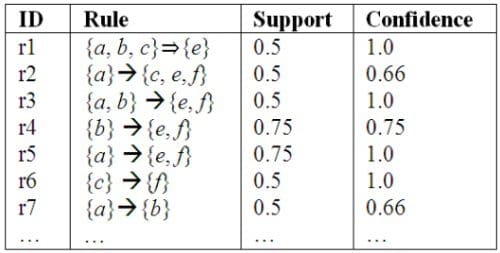
Apriori的算法其实很简单,就是找出所有满足支持度和置信度小阈值的规则。但是候选的集合会随着商品数量的增加而呈指数式增长。
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责,本站只提供参考并不构成任何投资及应用建议。本站是一个个人学习交流的平台,网站上部分文章为转载,并不用于任何商业目的,我们已经尽可能的对作者和来源进行了通告,但是能力有限或疏忽,造成漏登,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。

